زمان تخمینی مطالعه: 16 دقیقه
آموزش پردازش موازی در OpenSees موضوع چند دوره آموزشی در خانه OpenSees است. در این نوشته به بیان مطالب مهمی در مورد این موضوع می پردازیم. امیدواریم این توضیحات به شما در رسیدن به هدفتان کمک مؤثری بکند. در صورت نیاز به دریافت کمک بیشتر، ما مشتاقانه در خدمت خواهیم بود. دوره های خانه OpenSees که در ارتباط با این موضوع تهیه شده اند، مثل همیشه شما را مستقیم و به سرعت به مقصد خواهند رساند.
هدف از پردازش موازی با OpenSees چیست؟
احتمالا با جواب این سؤال تا حدی آشنا باشید. با این حال، بد نیست یک بار آن را با هم مرور کنیم. این سؤال با 2 انگیزه مختلف ممکن است مطرح شود:
- پردازنده یا CPU رایانه ما بیش از 1 هسته دارد ولی انجام هر تحلیل به روش معمول فقط از 1 هسته استفاده می کند
- قصد داریم با بهره گیری از ظرفیت ابررایانه هایی مثل سیمرغ یا hpc دانشگاه صنعتی شریف سرعت تحلیل های خود را به حداکثر برسانیم.
اما سوالی که هر دو حالت باید پاسخ دهیم این است:
2 روش برای پردازش موازی با OpenSees
یک راه خیلی ساده برای مشغول کردن همزمان چند پردازشگر در زمان تحلیل وجود دارد. این راه، اجرای همزمان چند OpenSees عادی است که به آن sequential و پشت سر هم و یا غیرموازی می گویند (تذکر: در این نوشته، هر جا کلمه OpenSees را به کار می بریم منظور ما همین نسخه غیرموازی است). به زبان ساده، فرض کنید ما میخواهیم تحلیل های IDA غیرموازی را طبق آموزش های خانه OpenSees اجرا کنیم. در آنجا توصیه ساده ای کردیم تا بتوانیم مثلا 40 رکورد زلزله را به کمک 8 هسته و به طور همزمان به یک مدل اعمال کنیم. آن روش این بود که لیست رکوردهای زلزله را به 8 دسته تقسیم کنیم. سپس، 8 پنجره همزمان از نرم افزار OpenSees را باز کنیم و در هر کدام یکی از این دسته ها را به عنوان ورودی داده و کد را اجرا کنیم.
این راه حل به ما کمک می کند تا حدی از ظرفیت پردازش همزمان هسته های CPU استفاده کنیم. با این حال، نمی توان این راه حل را یک روش پردازش موازی در OpenSees نامید. در واقع، «مدیریت بهینه توان پردازشگر» حلقه مفقوده روش های ساده مبتنی بر اجرای دستی و همزمان کدهای OpenSees است. در واقع، تحلیل هر یک از برنامه های OpenSees همزمان در زمانی متفاوت از سایرین تمام می شود. حال، اگر ما نظارت مداومی بر زمان اتمام تحلیل ها نداشته باشیم، نمی توانیم بلافاصله پس از اتمام یک تحلیل، تحلیل جدیدی را به آن پردازشگر بسپاریم. در نتیجه، آن پردازشگر در یک بازه زمانی که ممکن است طولانی باشد بیکار خواهد ماند. از سوی دیگر، انجام یک نظارت مداوم نیز زمان بسیاری از ما خواهد گرفت. ضمنا، هر چه تعداد هسته ها بیشتر شود، جلوگیری از اتلاف زمان پردازشگرها دشوارتر خواهد شد. پس باید به دنبال یک راه حل دقیق و برنامه نویسی شده باشیم. استفاده از چنین روشی به طور ویژه برای ابرکامپیوترها ضروری خواهد بود.
به طور کلی، دو دسته روش برای تحلیل چند هسته ای با OpenSees وجود دارد که در این نوشته مفصلا در مورد آنها صحبت خواهیم کرد.
تحلیل موازی به کمک OpenSeesSP و OpenSeesMP
در OpenSees (نسخه غیرموازی) زمانی که ما دستور analyze را فراخوانی می کنیم، تنهای یکی از هسته های پردازشی کامپیوتر فعال می شود. دو نسخه موازی OpenSeesSP و OpenSeesMP برای توزیع فرایند تحلیل روی هسته های بیشتر ایجاد شده اند. شاید برایتان جالب باشد که بدانید پردازش موازی با OpenSees، نوآوری اصلی پایان نامه دکتری آقای McKenna نویسنده این نرم افزار بوده است. حال می خواهیم ببینیم این دو نسخه موازی دقیقا چگونه کار می کنند و چه تفاوتها و مزایایی دارند؟
اساس روش این دونسخه را می توان در یک جمله کوتاه خلاصه کرد:
فرایند موازی سازی در OpenSeesMP
به منظور اجرای تحلیل روی هسته های متعدد، OpenSeesMP ابتدا یک پردازشگر مرکزی را مسئول مدیریت فرایند کلی تحلیل می کند. این پردازشگر در شروع تحلیل، مدل سازه ای را به بخش های متعددی تقسیم میکند. هر کدام از این بخش ها یک زیردامنه یا subdomain هستند. در طی فرایند تحلیل، محاسبات گره ها و المانهای هر زیردامنه به یک پردازشگر مجزا سپرده می شود. پس از آن، دستگاه معادلات توسط پردازشگر مرکزی تشکیل و به چند دستگاه کوچکتر بخش بندی (partition) می شود. در نهایت، حل هر دستگاه نیز توسط یک پردازشگر جدا انجام می شود. چنانکه می بینید، بعضی از مراحل فرایند تحلیل توسط پردازشگر مرکزی و به صورت غیرموازی انجام می گیرد.
از منظر مدیریت کد متن (source code)، در OpenSeesMP شئ analysis و محاسبات آن توسط پردازشگر مرکزی مدیریت می شود. پردازشگر مرکزی یک فرایند (process) محاسباتی است که شناسه (process id: pid) آن عدد 0 است. بر روی سایر فرایندها، یک شیء actor مسئول مدیریت محاسبات زیردامنه مربوطه می شود. محاسبات هر زیردامنه شامل موارد زیر است:
- بروزرسانی وضعیت المانها برای جابجایی گام جدید
- محاسبه نیروی نامتعادل در گره ها
پس از اجرای موازی محاسبات زیردامنه ها، فرایند مرکزی مسئول تشکیل دستگاه معادلات می شود. این مرحله خود شامل تجمیع (اسمبل کردن) نیروهای نامتعادل گره ها و تشکیل بردار نیروهای نامتعادل سازه است. این بردار سمت راست دستگاه معادلات را تشکیل خواهد داد. برای تشکیل سمت چپ دستگاه، باید ماتریس سختی سازه از تجمیع ماتریس سختی المانها تشکیل شود. کتابخانه MUMPS مسئول قسمت بندی دستگاه معادلات و حل موازی آن است. این کتابخانه به چند کتابخانه جبر ماتریسی دیگر نیز وابسته است به همین دلیل به آنها کتابخانه های طرف ثالث (third party) گفته می شود.
نقش زیردامنه به زبان ساده
به زبان ساده، مکانیزم پردازش موازی با OpenSeesMP شبیه به یک عکس پاناروما است. در این عکس، عکسهای دنباله دار متعدد که شامل درصدی هم پوشانی باشند گرفته میشوند. در انتها این عکسها از بخشهای مشترک آنها بر هم منطبق میشوند تا یک عکس یکپارچه و عریض تولید شود (شکل 1).
همانند عکس پاناروما، پردازش موازی روی زیردامنه های مختلف نیز نیاز به هم پوشانی دارد. به بیان دیگر، بخش هایی از محاسبات باید 2 یا چند بار انجام شوند. تعداد تکرارهای لازم بستگی به هندسه و مرزبندی زیردامنه ها دارد.
به عنوان مثال، یک حجم مکعب مستطیلی را در نظر بگیرید که می خواهیم با پردازش موازی در OpenSees تحلیل کنیم. در حالت 1، گره های تعریف شده در سطح این حجم را به 4 ناحیه موازی تقسیم میکنیم (شکل 1).

در حالت 2 (شکل 2)، این تقسیم بندی با نصف کردن اضلاع به دست می آید. طی هر دو تقسیم بندی، مرزهایی از گره های مدل تشکیل می شوند.
مرزهای تشکیل شده در حالت 1 فقط بین دو ناحیه مجاور مشترک اند. اما در خصوص حالت 2، محاسبات ستونی از گره ها واقع در مرکز این مدل 4 بار در زیردامنه های مختلف تکرار می شود. چنانچه می بینیم، با تغییر دادن روش تقسیم مدل به زیردامنه ها می توان کارایی آن را تغییر داد. در بخش بعد، به بیان دقیقتر و کمی مفهوم کارایی در تحلیل موازی به روش زیردامنه می پردازیم.

کارایی روش زیردامنه
اگر درصد افزایش سرعت را به درصد افزایش توان محاسباتی تقسیم کنیم، کارایی یک روش پردازش موازی به دست می آید. کارایی روش زیر دامنه همیشه کمتر از ۱۰۰٪ خواهد بود. دو علت برای افت کارایی در این روش وجود دارد:
- عدم مشارکت هسته های دیگر در محاسبات پردازش مرکزی
- وجود همپوشانی و محاسبات تکراری در زیر دامنه ها.
به علاوه، با افزایش تعداد پردازشگرها، کارایی پردازش موازی با OpenSeesMP مرتبا کم و کمتر می شود. دلیل این امر آن است که به ازای هر پردازشگر باید یک زیردامنه جدید تعریف شود. به این ترتیب، تعداد نواحی همپوشانی با افزایش تعداد پردازشگرها افزایش می یابد. پس مشاهده می شود که کارایی این روش تابع تعداد پردازشگرها و همینطور هندسه مدل است.
جدول زیر مثالی از کاهش کارایی با افزایش تعداد هسته دادنشان می دهد.
| تعداد پردازشگر (n) | نسبت افزایش سرعت تحلیل (p) | کارایی = p/n |
|---|---|---|
| 2 | 1.8 | 0.9 |
| 4 | 3 | 0.75 |
| 8 | 5 | 0.62 |
پردازش موازی در OpenSeesSP
OpenSeesSP یک راه حل نسبتا ساده برای افزایش سرعت به کمک پردازش موازی است. در این نسخه از روش زیردامنه استفاده نمی شود. به همین دلیل، محاسبات مربوط به گره ها و المانهای سازه به صورت موازی و همزمان انجام نمی شوند. در عین حال، حل دستگاه معادلات، همانطور که در مورد OpenSeesMP گفته شد، همچنان به صورت موازی انجام می شود.
به عبارتی، آنچه در OpenSeesSP تقسیم بندی می شود دستگاه معادلات و ماتریس سختی مدل است. بنابر این، تفاوت OpenSeesSP با نسخه غیرموازی OpenSees تنها در پشتیبانی از کتابخانه MUMPS است. این کتابخانه که در بالا در مورد آن صحبت شد، توسط دستور system در OpenSeesMP و OpenSeesSP احضار می شود.
نصب نسخه های موازی OpenSees
متاسفانه در حال حاضر (در سال 2022)، یک مشکل جدی در مسیر پردازش موازی با OpenSees وجود دارد. این مشکل مربوط به پشتیبانی های به عمل آمده از نسخه های OpenSeesMP و OpenSeesSP است. کامپایل کردن متن نرم افزار جهت تولید فایلهای باینری (با پسوند exe) یک کار تخصصی و نسبتا دشوار است. در نسخه غیرموازی، روال های کامپایل کردن کتابخانه ها به خوبی تشریح و برای سیستم های عامل مختلف تا حد زیادی مهیا شده است. با این وجود، برای نسخه های موازی یعنی OpenSeesSP و OpenSeesMP این کار به صورت کامل انجام نگرفته است. شکایتهای کاربران از مشکلات مرتبط با این موضوع گواه خوبی بر این ضعف پشتیبانی است.
همینطور، از ارائه آخرین فایل کامپایل شده نسخه های موازی توسط سایت رسمی OpenSees سالهاست که میگذرد. این در حالی است که ارائه برنامه کامپایل شده نسخه غیرموازی برای سیستم های عامل ویندوز و مک به طور مرتب انجام می گیرد. به دلیل این قبیل مشکلات، اخیرا استفاده از این نسخه ها با دشواری جدی روبرو است. با این حال، اگر علاقه مند به استفاده از نسخه های موازی یعنی OpenSeesSP و OpenSeesMP هستید، توصیه میکنیم به مطالعه این اسلایدها بپردازید.
نصب این دو نسخه موازی کار چندان دشواری نیست ولی متکی به نصب یک کتابخانه متن باز دیگر به نام MPICH2 است.
اگر مایلید از آخرین اخبار ما در خصوص آموزشها و بروزرسانی های این نسخه ها مطلع شوید، از طریق فرم تماس با خانه OpenSees با ما در ارتباط باشید.
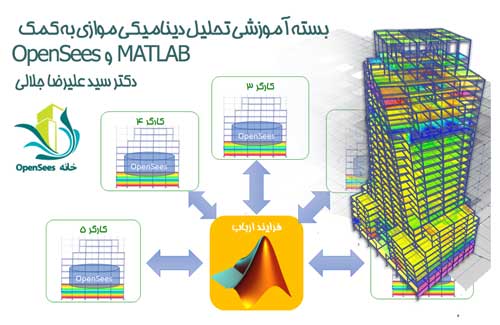
تحلیل موازی OpenSees به کمک MATLAB و پایتون
در این قسمت می خواهیم به شما یک روش ساده، در دسترس و در عین حال کارامد را معرفی کنیم. این روش در موارد بسیاری جایگزین کاربرد مستقیم روش های پردازش موازی با OpenSees مورد اشاره در بالا خواهد شد. در اصل، ما به دنبال ارائه نسخه برنامه نویسی شده و تکامل یافته همان روش ساده و دستی هستیم که در ابتدای این نوشته معرفی کردیم. این روش بجای تقسیم بندی مدل و محاسبات اجزای محدودی آن، نگاه خود را به تعداد تحلیلهایی که قرار است روی هر مدل انجام شود معطوف میکند. روش کلی که این هدف برای درگیر کردن پردازشگرهای متعدد استفاده می کند را می توان اینگونه خلاصه کرد:
همانطورکه مشخص است، این روش به ساختار اجزای محدودی محاسبات کاری ندارد. بلکه، از روش کلی که در انجام محاسبات موازی وجود دارد تبعیت می کند. یک روش خیلی مرسوم در انجام محاسبات موازی روش server-client است. این روش که از آن با عنوان master-worker نیز یاد می شود مورد استفاده خانه OpenSees برای پیاده سازی تحلیل IDA موازی با الگوریتم Hunt-Fill نیز بوده است. جزئیات پیاده سازی روش server-client برای انجام تحلیل های لرزه ای اولین بار در سال 2011 و توسط Vamvatsicos پیشنهاد شد.
در روش server-client، یک هسته محاسباتی که به آن server و یا ارباب (master) گفته می شود نقش مدیر را بازی می کند. سایر هسته ها با ایفای نقش client و یا کارگر (worker) مسئول انجام تحلیل ها می شوند. پردازشگر مدیر با در نظر گرفتن کل تحلیل هایی که باید انجام شوند، اقدام به توزیع آنها در بین پردازشگرهای کارگر میکند.
پیاده سازی تحلیل های موازی در OpenSees از نوع تاریخچه زمانی cloud نسبتا ساده است. دلیل این سادگی استقلال بین رکوردهای مختلف زلزله و فرایند تحلیل سازه تحت آنهاست. بر خلاف روش cloud، در الگوریتم Hunt-Fill تحلیل های دینامیکی مختلفی که بر روی سازه انجام می شوند به یکدیگر وابسته اند. به عبارت دقیقتر، شدت هایی که رکوردهای مختلف زلزله باید به آن مقیاس شوند از ابتدا مشخص نیستند. بنابراین، پردازشگر مدیر باید از قانون پیچیده ای تبعیت کند تا بر اساس پاسخ سازه تحت شدتهای قبلی، در مورد شدت های بعدی تصمیم گیری کند. برای درک این وابستگی شما را به دیدن ویدیوی رایگان الگوریتم های تحلیل IDA دعوت می کنیم.
برای توزیع تحلیل ها روی پردازنده های متعدد می توان از ابزارهای مرسوم مانند MATLAB و پایتون کمک گرفت. آشنایی با قابلیتهای پردازش موازی در این محیط های برنامه نویسی نیاز به قدری مطالعه و تمرین دارد. پس از کسب تسلط لازم، به راحتی می توان نسخه غیرموازی OpenSees را بر روی هسته های پردازشی مختلف فراخوانی کرد. هر یک از این هسته ها نقش کارگر را بر عهده خواهند گرفت. کدنویسی پردازنده های کارگر شامل نوشتن یک تابع است که اطلاعات هر تحلیل را گرفته و آن را اجرا کند. پس از نوشتن این تابع، کافی است با استفاده از یک کد مناسب نقش پردازشگر مدیر را نیز پیاده سازی کنیم. همانطور که گفته شد این کد برای انواع مختلف تحلیل اشکال متفاوتی دارد.
کارایی روش master-worker تابع طول زمانی است که به علت رسیدن به انتهای مجموعه تحلیل ها، بعضی از کارگرها بیکار می مانند. در این فاصله، درصد اشغال پردازشگر به تدریج از 100 به 0% می رسد. هر چه این زمان طولانی تر شود، کارایی محاسبات موازی کمتر خواهد شد. با این حال، کارایی این روش اغلب بالای ۸۰٪ است. بطور کلی، برای تعداد هسته ثابت، با افزایش تعداد تحلیلها و زمان مورد نیاز برای هر کدام، کارایی افزایش پیدا میکند.
به عنوان مثال، یک قاب خمشی ۱۰ طبقه ۲بعدی با المانهای ماکرو را در نظر بگیریم. اگر این قاب را تحت ۵۰۰ تحلیل دینامیکی غیرخطی با ۸ هسته قرار بدهیم، راندمان بالای ۹۵٪ خواهد بود. با این حال، با افزایش تعداد هسته ها به ۴۸ تا، راندمان تا حدود ۹۰٪ کاهش خواهد یافت.
پردازش موازی در مهندسی زلزله
با توجه به توضیحات ارائه شده در بالا یک سؤال مهم در خصوص تحلیل دینامیکی موازی با OpenSees مطرح می شود. کدام یک از 2 روش معرفی شده، کاربرد بیشتری در مهندسی زلزله و ارزیابی عملکرد سازه ها دارند؟
همانطور که احتمالا می دانید، مسائل مطرح شده در مهندسی زلزله اغلب حائز 2 ویژگی هستند:
- سازه های مورد مطالعه اغلب به روش ماکرو مدلسازی می شوند. این دسته از مدلها اغلب حجمی در حد کم و یا متوسط دارند.
- برای در نظر گرفتن عدم قطعیت لرزه ای نیازمند انجام تحلیل های دینامیکی خیلی زیاد هستند.
همانطور که گفته شد، در مدلهای با حجم کم یا متوسط، تحلیل موازی با OpenSeesSP و OpenSeesMP تنها برای تعداد هسته های کم منطقی است. بنابراین، در صورت در اختیار داشتن هسته های زیاد (8 تا یا بیشتر) باید به سراغ تحلیل موازی با MATLAB یا پایتون رفت. در واقع، بالا بودن تعداد کل تحلیل های دینامیکی شرایط را برای بهره گرفتن از روش دوم فراهم می کند. به این دلایل، سادگی استفاده از روش دوم را نیز باید اضافه کرد. این سادگی مربوط به مشکلات مربوط به کامپایل کردن و نصب نسخه های موازی است که در بالا به آن اشاره شد. بنابراین،